



 9,460
9,460
Поисковые системы далеко не сразу вносят в свои базы данных новые страницы сайтов. Процесс индексирования может занять недели и месяцы. А это уже прямая помеха для SEO. Рассмотрим, что такое «краулинговый бюджет» и почему его нужно оптимизировать.
Что такое краулинговый бюджет
Краулинговый бюджет (или лимит обхода) – это то количество страниц, которые поисковый робот может просканировать на сайте за один раз. Или ещё проще: это количество обновленных страниц, которые вы можете представить поисковому роботу за один его визит.

Это число может немного меняться, но достаточно стабильно. Важно понимать, что этот лимит отличается от сайта к сайту. Популярный старый сайт сканируется постоянно, новый – с большими задержками и помалу.
Причина проста: ресурсы поисковых систем небезграничны. Никаких дата-центров не хватит, чтобы мгновенно отследить все изменения на миллиардах сайтов по всему миру. Особенно если речь идёт о мусорных, малополезных и непопулярных ресурсах. Если бот сканирует низкокачественные страницы – бюджет сокращается. А с ним – и успехи в продвижении.
Почему это вообще важно: робот сканирует определенное количество страниц, и может неправильно сортировать адреса, то есть совсем не так, как нужно вам. Например, какая-нибудь служебная страница «О компании» получит больше хитов, чем новая товарная категория с новинками продуктов.
Можно ли повлиять на поисковые системы, чтобы увеличить это число? В какой-то мере – да. Ниже мы рассмотрим основные средства оптимизации лимита обхода страниц сайта поисковыми роботами.
Как работает краулинг
Поисковый робот получает список URL для обхода на сайте, и периодически обходит его. Каким образом формируется этот список? Его составляют:
- внутренние ссылки на сайте, включая средства навигации;
- карта сайта в формате XML (sitemap.xml);
- внешние ссылки.
Для того, чтобы понять, может ли URL попасть в список обхода, поисковый робот периодически сверяется с файлом robots.txt, содержащий запреты и разрешения. Если URL не запрещен – он попадёт в список обхода. Но имейте в виду: директивы из списка robots.txt – это не команда роботу. Это ваше пожелание, рекомендация. И в некоторых случаях URL всё равно попадёт в индекс, потому что в индекс уже попали ссылки на страничку, или настроено перенаправление, или робот нашёл другие сигналы, убеждающие его в важности запрещенного URL. Он решит, что это какая-то ошибка, и продолжит сканировать страницу, а Google вам будет писать письма «проиндексировано несмотря на запрет».
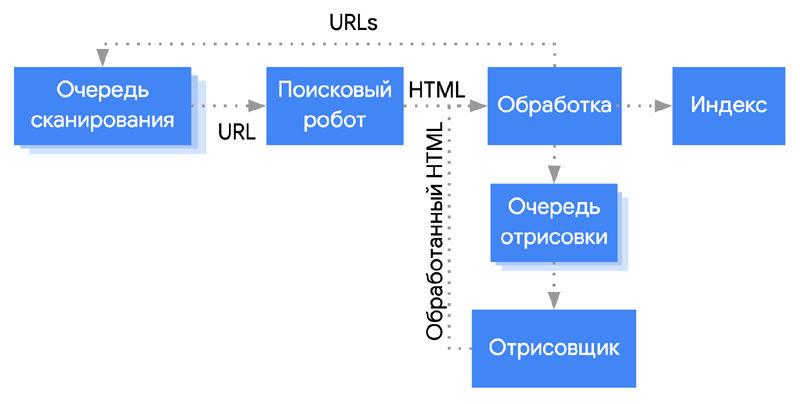
Процесс краулинга лучше описан для роботов Google благодаря тому же Гэри Иллису (Gary Illyes). Google создаёт список URL и сортирует их по приоритетности. Затем начинается сканирование по списку, сверху донизу.
Как определяются приоритеты? – В первую очередь Google учитывает PageRank страницы. Другие факторы – карта сайта, ссылки и многое другое.
После того, как робот-краулер просканировал URL и проанализировал его контент, он добавляет новые адреса в список обхода, чтобы обойти их позже или сразу.
Нет точного способа составить список причин, по которым поисковый робот просканирует URL или не станет это делать. Но если уж решит, что должен – обязательно просканирует. Когда-нибудь. А вот когда – частично зависит и от вас.
Как определить проблему с краулинговым бюджетом
Если поисковый робот находит на вашем сайте много ссылок, и выделяет вам большое число для лимита – всё хорошо. Но что делать, если ваш сайт – сотни тысяч страниц, а лимит небольшой? В таком случае вам придётся ждать месяцами, прежде чем поисковая система заметит какие-то изменения на страницах.
Чтобы понять, есть ли у вас проблема с краулинговым бюджетом, можно сделать следующее:
- Определите, сколько страниц на вашем сайте должно быть в индексе (они не закрыты мета-тегом NOINDEX и не запрещены в robots.txt).
- Зайдите в инструменты вебмастеров Google и Яндекс. Сопоставьте количество проиндексированных страниц с количеством страниц вашего сайта.
- В зависимости от поисковой системы используйте инструменты «Статистика обхода» или «Статистика сканирования». В Яндекс всё наглядно и бессистемно (см. скриншот). Может вообще не сканировать, может – до чего дотянется. Google более методичен.
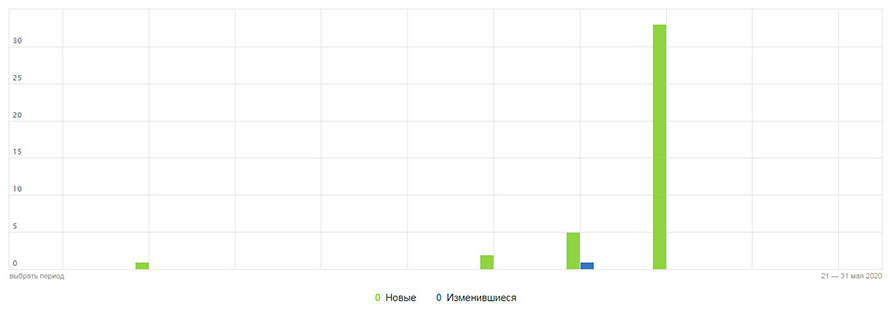
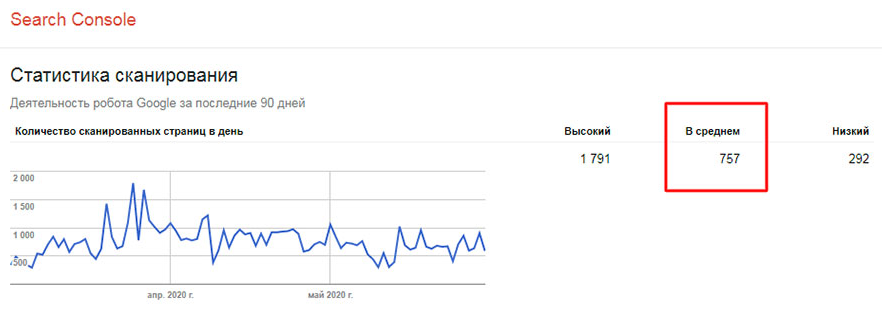
- Разделите число страниц на среднее число просканированных за день. Если результат в 10 раз больше страниц, сканируемых поисковиком за день, то вам однозначно надо задуматься об оптимизации лимита обхода. Если число меньше 3, у вас всё отлично.
Полезно сопоставить количество страниц в индексах Яндекс и Google. Правила обхода этих систем отличаются, но разница не должна быть существенной. А отличия в наборе данных панелей вебмастеров помогут вам получить дополнительные сведения и инсайды.
Как увеличить бюджет сканирования
Пунктов здесь достаточно много, поэтому мы начнём с самых простых по мере усложнения. Однако все эти способы эффективны.
Общий принцип, который надо усвоить: любая ранее проиндексированная страница, которую поисковый робот не может просканировать несколько раз подряд, выбрасывается из индекса. Это касается как страниц, недоступных по техническим причинам (500-е ошибки, например), так и страниц, закрытых от индексирования намеренно, например, с помощью тега NOINDEX.
В Google такой процесс деиндексации – долгий, он занимает месяцы с периодическими проверками, не стала ли страница доступной. Яндекс выбросит «битую» страницу быстрее, но если причины проблемы не устранены, будет возвращать её в индекс и снова выбрасывать.
Избавьтесь от ошибок
Для нормально настроенного сайта есть только два типа допустимых ответов сервера: 200 (ОК) и 301 (постоянный редирект). Притом 200 OK должно существенно преобладать над 301. Всё остальное требует пристального рассмотрения и исправления. И вот почему.
- Если вы по какой-то причине вместо постоянного перенаправления 301-м редиректом использовали временный 302, то робот поймёт вас буквально: контент временно недоступен, никуда его не удаляем и периодически проверяем, как там дела. Это напрасный расход лимитов в явном виде.
- Второй пример – это использование кода 404 (не найдено) вместо кода 410 (удалено окончательно). Логика проста: раз удалено – выбрасываем из индекса и забываем. А 404 означает, что если не нашли, то найдём в следующий раз. Опять слив бюджета, если страница реально удалена и больше не появится.
- При этом страница, отдающая 404, может собирать ссылочный вес, который в этом случае сливается впустую. Самое разумное тут: составить список 404-х и проанализировать, можно ли настроить редирект на эквивалентную или похожую страницу.
- Ну и уж совсем безобразно, если сервер регулярно отдаёт 500-е. Это явный признак некачественного ресурса, на который робот будет заходить всё реже, а сканировать – всё меньше.
Если вы видите такое в логах или результатах проверки SiteAnalyzer, Screaming Frog SEO Spider или их аналогов – выясняйте причины и принимайте срочные меры.
Ещё один важный источник информации об ошибках – это инструменты вебмастеров. Яндекс-Вебмастер, например, вообще предлагает включить мониторинг важных страниц, чтобы вы могли своевременно получать уведомления об ошибках. Не игнорируйте эту возможность.
Избавьтесь от дублей и мусора
В индекс не должны попадать служебные страницы, пользовательские, дублирующие другие страницы, страницы фильтров, сравнений товаров, страницы с UTM-метками, параметрами и ID сессий, страницы-черновики. Закрывайте их от индексирования с помощью robots.txt.

Особенно часто проблема дублирования встречается на сайтах электронной коммерции. Один и тот же контент доступен по разным адресам. Речь идёт о страницах сортировки, фильтрации, внутреннем поиске и т.п. Часто во время аудита можно видеть, что в индекс попадают страницы сравнения товаров и пользовательские сессии вообще – вплоть до содержимого «Корзины».
Главное правило: сохраняйте только одну версию URL!
В некоторых случаях просто так закрыть дублирующую страницу от робота нельзя чисто технически. В таком случае используют тег Canonical, объясняющий роботу, какая страница должна быть в индексе, а какую можно проигнорировать. В таком случае Canonical действует как мягкий 301-й редирект.
Пример такого случая: товарная карточка входит в две разные товарные категории, и выводится с разными URL. Получается, что у вас две одинаковые страницы с разными адресами. Поисковые системы склеивают такие страницы и что-то выбросят из индекса. А потом могут внести опять. А потом опять выбросить. Чтобы избежать такой чехарды и напрасной траты краулингового бюджета – настройте Canonical, если система управления контентом сайта лучшего решения не предоставляет.
Ещё один вариант: использовать мета-тег NOINDEX. Однако имейте в виду: такие страницы всё ещё сканируются, просто реже разрешенных. И, следовательно, бюджет продолжает расходоваться впустую. И не забудьте к NOINDEX обязательно добавить Follow: такая страница может собирать PageRank, так что стоит отдать его более важным страничкам.
Чтобы избавиться от дублей окончательно, нужны более радикальные меры, чем директивы для ботов. Оптимально – оценить возможность удаления дублирующегося контента.
Пример: варианты одного и того же продукта, отличающегося минимальными параметрами и свойствами (цвет, размер и прочее, если они не имеют значения для покупателя).
Уменьшайте количество перенаправлений
Первое, с чего начинается технический аудит сайта – это проверка перенаправлений на главную страницу. Страница может быть доступна по HTTP или HTTPS, а также с WWW и без него. Это дубли, и в таком случае поисковая система может счесть главным зеркалом любую из этих версий, а вы потеряете контроль – и краулинговый бюджет. Поэтому в обязательном порядке нужно настраивать 301-й (постоянный) редирект на выбранную вами версию.
Однако останавливаться на этом нельзя: надо убедиться, что используется единственный редирект. При неграмотной настройке перенаправления вы можете получить цепочку из двух-трёх перенаправлений. Это плохо, и вот почему: поисковый робот видит новые URL и добавляет их в свой план обхода. Но это вовсе не значит, что он пойдёт по этим URL прямо сейчас. И чем длиннее цепочка редиректов – тем дольше процесс. Сканирование затягивается.
Вот типичный пример плохо настроенного редиректа при переходе на безопасный протокол HTTPS:

Ещё одна проблема с лишними редиректами – это ссылочный вес. Каждое перенаправление уменьшает его, поэтому ваш линкбилдинг работает менее эффективно.
Ну и разумеется, проверять на двойные перенаправления надо не только главную страницу. Если в процессе анализа посещений страниц вы видите проблемные моменты – не забудьте проверить и редиректы.
Для проверок рекомендую использовать majento.ru.
Настройте карту сайта sitemap.xml
Эта карта должна содержать полный перечень страниц, которые должны быть в индексе. Только важное! Поисковые системы используют её для навигации и в какой-то мере для получения указаний по приоритетам. В sitemap.xml может содержаться информация о дате создания, последнего изменения, присвоенного вами приоритета по важности, частоте обхода и т.д.
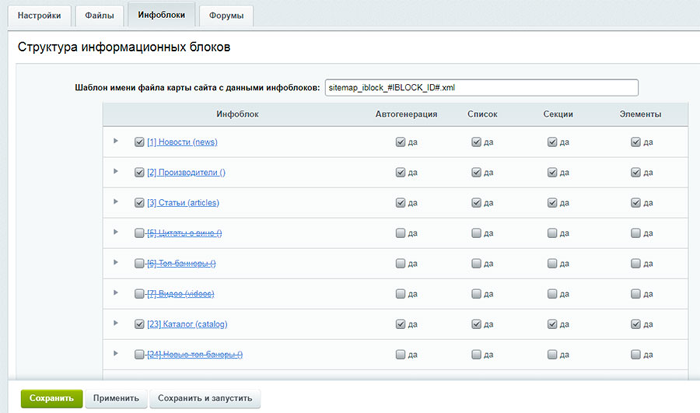
Однако не нужно думать, что робот обязательно учтет ваши указания. Фактически вы можете рассчитывать только на то, что робот увидит ваш список URL для обхода и рано или поздно воспользуется им. Всё остальное, как правило, игнорируется во избежание манипуляций. Однако это вовсе не значит, что этих директив быть не должно. Делайте, что можете, просто не рассчитывайте на эффект.
Далеко не каждая CMS позволяет создавать карту сайта в соответствии с вашими планами, и туда может попасть много мусора. Хуже того, некоторые CMS вообще не умеют такие карты сайта создавать. В таких случаях используются сторонние плагины или даже ручная загрузка карты сайта, сформированной каким-то ПО или внешним сервисом.
Некоторые специалисты рекомендуют удалять даже нужные URL из карты сайта после того, как странички попали в индекс. Не надо так делать, потому что это также может плохо повлиять и на краулинговый бюджет.
Периодически проверяйте sitemap.xml – в ней не должно быть удаленных страниц, URL с перенаправлениями и ошибками.
Проработайте структуру сайта
Это, пожалуй, один из наиболее трудно реализуемых пунктов: полная реструктуризация уже работающего сайта – дело непростое. Конечно, проще сделать правильно на стадии разработки.
Структуру сайта, на котором любая страница доступна не более, чем за 4 клика от главной, принято считать плоской. Глубокой называют архитектуру сайта с вложенностью от 5 кликов от главной страницы.
Главный принцип: глубокие сложные вертикальные структуры сайтов сканируются намного сложнее, чем плоские структуры. Да и посетителям нужно серьезно постараться, чтобы найти интересующий контент. А если к этому добавить неэффективную навигацию, да ещё в мобайл – то вот вам и глобальная проблема для продвижения.
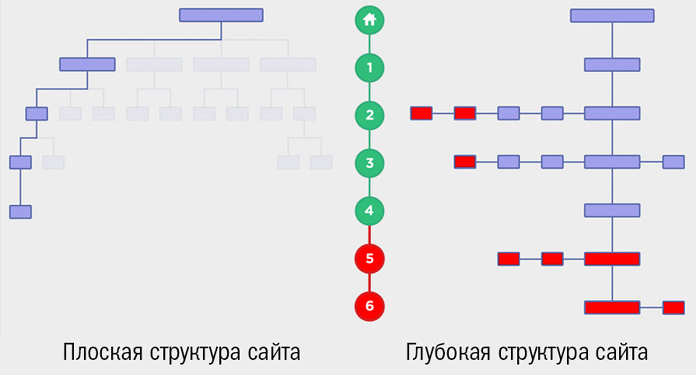
Используйте принципы плоской структуры сайта, чтобы важные страницы были как можно ближе к главной. Горизонтальная, «плоская» структура намного предпочтительнее вертикальной.
Однако не надо думать, что абсолютно плоская структура, лишённая группировки страниц по категориям, даст преимущество в продвижении только за счёт доступности. Нужно создать структуру, сочетающую доступность и логичность иерархии. Однако этот вопрос слишком глобален, чтобы рассматривать его в рамках темы краулинга.
Чтобы оптимизировать структуру, вам могут понадобиться достаточно нетривиальные методы, к тому же выходящие за рамки чисто технического SEO. Начать прежде всего стоит с визуализации существующей структуры: такое могут многие инструменты, использующиеся для аудита сайтов. На этой стадии вы как минимум можете внести небольшие корректировки наглядно оценивая несовершенство структуры сайта.
Для глобальных же изменений начните с семантики и группировки запросов. Смотрите, что можно связать, объединить, переместить на уровень выше. А что-то наверняка стоит удалить совсем.
Примечание. Здесь можно учесть разницу в ранжировании сайта в Яндекс и Google. Яндекс больше ценит объёмные сайты, даже в ущерб качеству контента. Сейчас, в 2020-м, это всё ещё актуально. Google объём за счёт мусорных страниц не оценит. Ищите компромисс.
Настройте заголовок Last-Modified
Это важный технический параметр, который разработчики сайтов и системные администраторы игнорируют практически всегда. И далеко не каждый SEO-специалист понимает важность такого ответа сервера. И напрасно.
Заголовок Last-Modified используется в нескольких целях:
- снижение нагрузки на сервер;
- ускорение индексации страниц;
- увеличение скорости загрузки.
Чем крупнее ваш сайт и чем чаще вы обновляете контент – тем важнее правильно настроить такой ответ сервера. Чаще же всего такого ответа нет вообще.
Как работает Last-Modified. Поисковый робот или браузер обращается к определенному URL, запрашивая страничку. Если страничка не менялась с последнего взаимодействия, сервер возвращает заголовок "304 Not Modified". Соответственно, нет необходимости загружать повторно контент, который уже есть в кэше и индексе. А вот если изменения были, то сервер вернет 200 OK, и новый контент будет загружен.
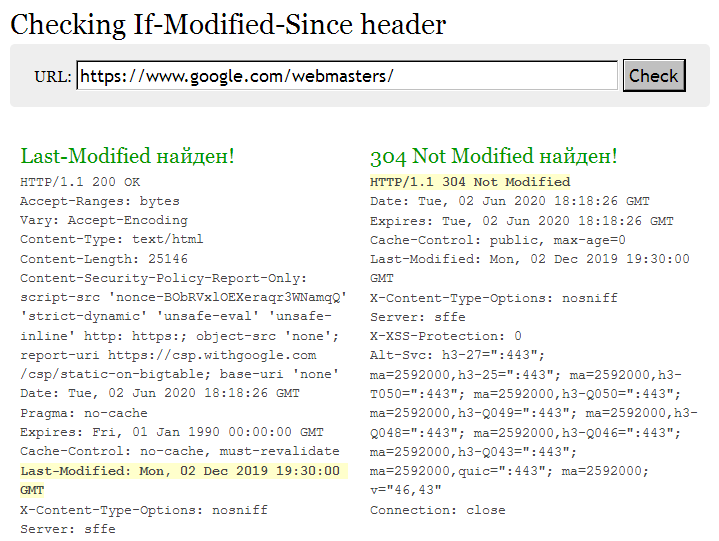
Кроме улучшения быстродействия, в поиске будет обновлена дата содержимого страницы. А это очень важно и как фактор ранжирования, особенно в сферах, связанных со здоровьем и финансами людей (YMYL).
Last-Modified позволяет роботу убрать из списка URL те страницы, что не обновлялись, и просканировать обновленные, то есть оптимизированные вами. Вы помогаете определить приоритеты и экономите краулинговый бюджет.
Примечание. Используйте Last-Modified на страницах с максимально статичным контентом. Сквозной блок с обновляющимся содержимым – совсем не то, что реально обновленный контент, и роботу это может не понравиться. Как минимум, снижайте количество таких блоков на посадочных страницах. То, что хорошо работает на главной – не нужно на других посадочных страницах.
Для проверки можно использовать last-modified.com или его аналоги.
Развивайте ссылочный профиль
Да, ссылки важны не только для усиления хостовых факторов и проработки текстовых. Если на сайте диагностируется проблема с индексацией – обратите внимание и на ссылочный профиль. Из всех средств оптимизации краулинга проработка ссылочного – самый медленный и трудоемкий путь, но в тоже время, и полезный.
И обратите внимание: речь идёт не только о внешних ссылках. Внутренние ссылки также ускоряют индексацию. Получив ссылку с часто сканируемой страницы, новая страница быстрее пойдёт в индекс. Вот почему в любой сфере рекомендуется выводить на главную блок с анонсами, чем бы они ни были – товарами или услугами.
То же самое касается ссылочного веса, передаваемого по внутренним ссылкам. Больше ссылок на страницу – выше её важность в глазах робота. Распределяйте ссылочный вес с умом. Для оценки распределения ссылочного веса постранично рекомендую использовать браузерное расширение для Chrome LinksTamed.
«Кольцевые» ссылки, «висячие узлы» и изолированные страницы
Эти два типа ошибок напрямую относятся к проработке внутренней перелинковки и становятся причиной проблем с краулингом и индексацией. По счастью – совсем небольших.
Кольцевая ссылка – это ссылка страницы на саму себя. Самый простой вариант – это активная «хлебная крошка», обозначающая саму страницу. Лучше всего снять с неё активную ссылку, чтобы она работала только как навигация, показывая посетителю, где именно он находится в данный момент. Но можно вовсе её убрать, юзабилити от этого не пострадает.
«Висячий узел» – это страница без исходящих ссылок. Она принимает ссылочный вес, но никуда его не отдаёт. Своего рода тупик для робота, которому больше некуда со страницы переходить. Чаще всего такие страницы не представляют серьезной проблемы, но нужно проанализировать характер такой страницы и по возможности внести корректировки.
Значительно большую проблему представляют собой изолированные страницы, на которые не ведёт ни одна ссылка. По счастью, в современных CMS это встречается редко. Например, по каким-то причинам страница не попадает в листинги категорий, её нет в навигации сайта, или того хуже – сайт взломан, и злоумышленники разместили там свой контент ради внешних ссылок. Оцените, нужна ли вообще эта страница, и если она должна быть проиндексирована – исправьте проблему.
Попросите роботов зайти
Хоть как-то повлиять на процессы индексации страниц можно и вручную, хотя тут речь идёт, скорее, вовсе не об оптимизации краулинга. Способов несколько.
Используйте переобход в панелях вебмастеров. И Яндекс, и Google позволяют вручную «скормить» системе измененные или новые URL и ускорить процесс обхода. используйте это. Главный минус процесса: ограничение в 20 URL в Яндекс и долгий (до 10 минут) процесс в Google, в течение которого вам ещё и капчу покажут неоднократно.
Делайте репосты в соцсети. Да, это до сих пор работает. Выберите соцсеть, которую роботы хорошо сканируют и постоянно мониторят, и закиньте туда ссылочку. Обычно используется либо Twitter, либо ВКонтакте. Экспериментируйте.
Сервисы-индексаторы. Такие сервисы позволяют закинуть неограниченное (как правило) количество URL, немного подождать – и за неделю в индекс таким маневром можно добавить несколько тысяч новых URL вне зависимости от краулингового бюджета. Проблема в том, что работает это только для Яндекс, и всё равно требует времени.
Изучаем логи
Изучение серверных логов даст вам максимум информации по маршрутам ботов и расписанию их обходов. Однако получить доступ к логам можно не всегда, это определяется типом хостинга. Если это проблема – лучше сменить хостера (привет, платформы сайтов-конструкторов!).
Если у вас нет навыков администрирования серверов, содержимое лога вас, безусловно, напугает. Слишком много данных, и преимущественно – ненужных. Если сайт небольшой – то с логами можно работать даже в Notepad++. А вот попытка открыть лог большого интернет-магазина «положит» ваш ПК на лопатки. В этом случае лучше использовать соответствующее ПО, позволяющее сортировать и фильтровать данные.
Для анализа можно использовать ПО для настольного компьютера, например, GamutLogViewer или Screaming Frog Log File Analyser (условно-бесплатный), либо внешние сервисы типа splunk.com. Но внешние сервисы обычно рассчитаны на большие объёмы данных, и стоят дорого.
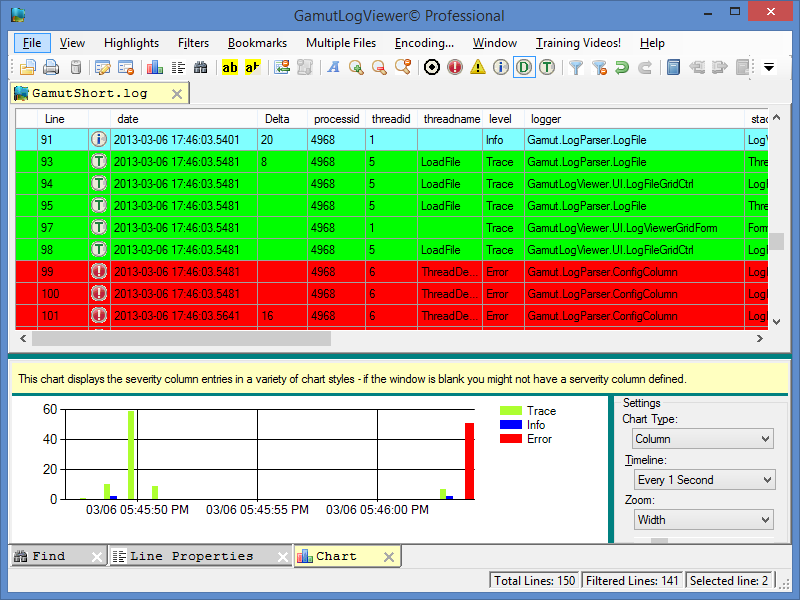
Есть проблема: не каждый GoogleBot, которого вы нашли в логах – действительно GoogleBot. Поэтому обращайте внимание на IP бота, и пробивайте его по WHOIS, чтобы отфильтровать фейки.
Ваша задача: обработать данные за достаточно большой период времени (месяц – оптимально) и найти некоторые закономерности. Среди них:
- Как часто заходит бот.
- Какие URL посещает чаще всего.
- Какие URL вообще игнорирует.
- Встречает ли ошибки и какие.
- Сканируется ли Sitemap.
- Какие категории отнимают больше всего ресурсов.
Получив такие данные, вы ответите на вопрос, ценит ли бот ваши целевые страницы, что он считает некачественным, чему отдаёт предпочтение. Например, можно выяснить, что робот предпочитает информационный раздел, сделанный как дополнение к магазину. А причина в том, что информационный раздел получает намного больше внутренних ссылок, а значит – и приоритет для робота.
Заключение
Оптимизация лимита сканирования (краулингового бюджета) – одна из важнейших частей технического SEO, поскольку слишком малый бюджет снижает эффективность продвижения. Вы внесли правки – вы ждёте изменения в ранжировании. Как понять, сработали ли принятые меры, если время прошло, а динамики никакой?
Если сайт в техническом отношении хорошо настроен, структурирован семантически, а объёмы его невелики, то особые ухищрения не нужны. Но небольшие улучшения краулинга пойдут на пользу в любом случае, так что потратьте немного времени на анализ и корректировки.

Автор статьи Виктор Петров
18 лет опыта в создании и продвижении сайтов. Меня зовут Виктор Петров, я специалист по информационному поиску и поисковой оптимизации, основанной на данных. Предлагаю услуги SEO-консалтинга и продвижения сайто... →
Другие статьи:




















{kind=link}