



 17,207
17,207
Примерно 60% пользователей сталкивается с тем, что новый сайт имеет проблемы с продвижением в поиске из-за неправильно настроенного файла robots.txt. Поэтому не всегда стоит сразу после запуска вкладывать все ресурсы в SEO-тексты, ссылки или внешнюю рекламу, так как некорректная настройка одного единственного файла на сайте способна привести к фатальным результатам и полной потере трафика и клиентов. Однако, всего этого можно избежать, правильно настроив индексацию сайта, и сделать это можно даже не будучи техническим специалистом или программистом.
Проверить качество оптимизации страницы можно с помощью бесплатного браузерного расширения SiteAnalyzer SEO Tools.
Что такое файл robots.txt?
Robots.txt это обычный текстовый файл, содержащий руководство для ботов поисковых систем (Яндекс, Google, etc.) по сканированию и индексации вашего сайта. Таким образом, каждый поисковый бот (краулер) при обходе страниц сайта сначала скачивает актуальную версию robots.txt (обновляет его содержимое в своем кэше), а затем, переходя по ссылкам на сайте, заносит в свой индекс только те страницы, которые разрешены к индексации в настройках данного файла.
User-agent: * Sitemap: https://somesite.com/sitemap.xml |
При этом у каждого краулера существует такое понятие, как «краулинговый бюджет», определяющее, сколько страниц можно просканировать единоразово (для разных сайтов это значение варьируется: обычно в зависимости от объема и значимости сайта). То есть, чем больше страниц на сайте и чем популярнее ресурс, тем объемнее и чаще будет идти его обход краулерами, и тем быстрее эти данные попадут в поисковую выдачу (например, на крупных новостных сайтах поисковые боты постоянно сканируют контент на предмет поиска новой информации (можно сказать что "живут"), за счет чего поисковая система может выдавать пользователем самые актуальные новости уже через несколько секунд после их публикации на сайте).
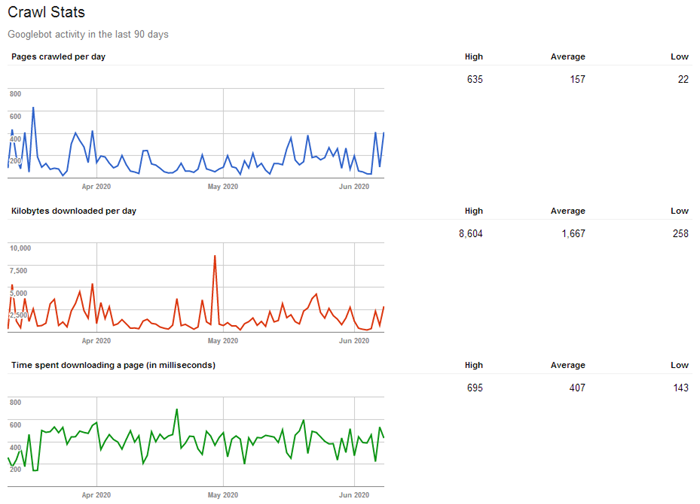
Таким образом, из-за ограниченности краулингового бюджета рекомендуется отдавать поисковым ботам в приоритете только ту информацию, которая должна обновляться или появляться в индексе поисковиков наиболее быстро (например, важные, полезные и актуальные страницы сайта), а все прочее устаревшее и не нужное можно смело скрывать, тем самым не распыляя краулинговый бюджет на не имеющий ценности контент.
Вывод: для оптимизации индексирования сайта стоит исключать из сканирования дубликаты страниц, результаты локального поиска по сайту, личный кабинет, корзину, сравнения, сортировки и фильтры, пользовательские профили, виш-листы и всё, что не имеет ценности для обычного пользователя.
Как найти и просмотреть содержимое robots.txt?
Файл размещается в корне домена по адресу somesite.com/robots.txt.
Данный метод прост и работает для всех веб-ресурсов, на которых размещен robots.txt. Доступ у файла открытый, поэтому каждый может просмотреть файлы других сайтов и узнать, как они настроены. Просто допишите "/robots.txt" в конец адресной строки интересующего домена, и вы получите один из двух вариантов:
- Откроется страница с содержимым robots.txt.
- Вы получите ошибку 404 (страница не найдена).
Вывод: если на вашем ресурсе по адресу /robots.txt вы получаете ошибку 404, то этот момент однозначно стоит исправить (создать, настроить и добавить файл на сервер).
Создание и редактирование robots.txt
- Если у вас еще нет файла, то нужно создать его с нуля. Откройте самый простой текстовый редактор (но не MS Word, т.к. нам нужен именно простой текстовый формат), к примеру, Блокнот (Windows) или TextEdit (Mac).
- Если файл уже существует, отыщите его в корневом каталоге вашего сайта (предварительно, подключившись к сайту по FTP-протоколу, для этого я рекомендую бесплатный Total Commander), скопируйте его на жесткий диск вашего компьютера и откройте через Блокнот.
Примечания:
- Если, например, сайт реализован на CMS WordPress, то по умолчанию, вы не сможете найти его в корне сайта, так как "из коробки" его наличие не предусмотрено. Поэтому для редактирования его придется создать заново.
- Регистр имени файла важен! Название robots.txt указывается исключительно строчными буквами. Также убедитесь, что вы написали корректное название, НЕ "Robots" или "robot" – это наиболее частые ошибки при создании файла.
Структура и синтаксис robots.txt
Существуют стандартные директивы разрешения или запрета индексации тех ли иных страниц и разделов сайта:
User-agent: * Disallow: /
В данном примере всем поисковым ботам не разрешается индексировать сайт (слеш через : и пробел от директивы Disallow указывает на корень сайта, а сама директива – на запрет чего-либо, указанного после двоеточия). Звездочка говорит о том, что данная секция открыта для всех User-agent (у каждой поисковой машины есть свой юзер-агент, которым она идентифицируется. Например, у Яндекса это Yandex, а у Гугла – Googlebot).
А, например, такая конструкция:
User-agent: Googlebot Disallow:
Говорит о том, что роботам Гугл разрешено индексировать весь сайт (для остальных поисковых систем директив в данном примере нет, поэтому если для них не прописаны какие-либо запрещающие правила, значит индексирование также разрешено).
Еще пример:
# директивы для Яндекса User-agent: Yandex Disallow: /profile/
Здесь роботам Яндекса запрещено индексировать личные профили пользователей (папка somesite.com/profile/), все остальное на сайте разрешено. А, например, роботу гугла разрешено индексировать вообще все на сайте.
Как вы уже могли догадаться, знак решетка "#" используется для написания комментариев.
Пример для запрета индексации конкретной страницы, входящей в блок типовых страниц:
User-agent: * Disallow: /profile/$
Данная директива запрещает индексацию раздела /profile/, однако разрешает индексацию всех его подразделов и отдельных страниц:
- /profile/logo.png
- /profile/users/
- /profile/all.html
Директива User-agent
Это обязательное поле, являющееся указанием поисковым ботам для какого поисковика настроены данные директивы. Звездочка (*) означает то, что директивы указаны для всех сканеров от всех поисковиков. Либо на ее месте может быть вписано конкретное имя поискового бота.
User-agent: * # определяем, для каких систем даются указания
Это будет работать до тех пор, пока в файле не встретятся инструкции для другого User-agent, если для него есть отдельные правила.
User-agent: Googlebot # указали, что директивы именно для ботов Гугла Disallow: / User-agent: Yandex # для Яндекса Disallow:
Директива Disallow
Как мы писали выше, это директива запрета индексации страниц и разделов на вашем сайте по указанным критериям.
User-agent: * Disallow: /profile/ #запрет индексирования профилей пользователей
Пример запрета индексации PDF и файлов MS Word и Excel:
User-agent: * Disallow: *.pdf Disallow: *.doc* Disallow: *.xls*
В данном случае, звездочка играет роль любой последовательности символов, то есть к индексации будут запрещены файлы формата: pdf, doc, xls, docx, xlsx.
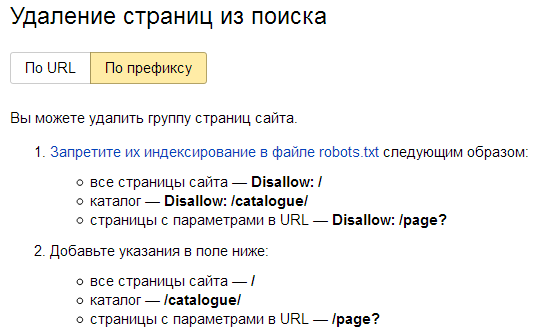
Примечание: для ускорения удаления из индекса недавно запрещенных к индексации страниц можно прибегнуть к помощи панели Яндекс Вебмастера: Удалить URL. Для группового удаления страниц и разделов нужно перейти в раздел "Инструменты" конкретного сайта и уже там выбрать режим "По префиксу".
Директивы Allow, Sitemap, Clean-param, Crawl-delay и другие
Дополнительные директивы предназначены для более тонкой настройки robots.txt.
Allow
Как противоположность Disallow, Allow дает указание на разрешение индексации отдельных элементов.
User-agent: Yandex Allow: / User-agent: * Disallow: /
Яндекс может проиндексировать сайт целиком, остальным поисковым системам сканирование запрещено.
Либо, к примеру, мы можем разрешить к индексации отдельные папки и файлы, запрещенные через Disallow.
User-agent: * Disallow: /upload/ Allow: /upload/iblock Allow: /upload/medialibrary
Sitemap.xml
Это файл для прямого указания краулерам списка актуальных страниц на сайте. Данная карта сайта предназначена только для поисковых роботов и оформлена специальным образом (XML-разметка). Файл sitemap.xml помогает поисковым ботам обнаружить страницы для дальнейшего индексирования и должен содержать только актуальные страницы с кодом ответа 200, без дублей, сортировок и пагинаций.
Стандартный путь размещения sitemap.xml – также в корневой папке сайта (хотя в принципе она может быть расположена в любой директории сайта, главное указать правильный путь к sitemap):
User-agent: Yandex Disallow: /comments/ Sitemap: https://smesite.com/sitemap.xml
Для крупных порталов карт сайта может быть даже несколько (Google допускает до 1000), но для большинства обычно хватает одного файла, если он удовлетворяет ограничениям:
- Не более 50 МБ (без сжатия) на один Sitemap.xml.
- Не более 50 000 URL на один Sitemap.xml.
Если ваш файл превышает указанный размер в 50 мегабайт, или же URL-адресов, содержащихся в нем, более 50 тысяч, то вам придется разбить список на несколько файлов Sitemap и использовать файл индекса для указания в нем всех частей общего Sitemap.
Пример:
User-agent: Yandex Allow: / Sitemap: https://project.com/my_sitemap_index.xml Sitemap: https://project.com/my_sitemap_1.xml Sitemap: https://project.com/my_sitemap_2.xml ... Sitemap: https://project.com/my_sitemap_X.xml
Примечание: параметр Sitemap – межсекционный, поэтому может быть указан в любом месте файла, однако обычно принято прописывать его в последней строке robots.txt.
Clean-param
Если на страницах есть динамические параметры, не влияющие на контент, то можно указать, что индексация сайта будет выполняться без учета этих параметров. Таким образом, поисковый робот не будет несколько раз загружать одну и ту же информацию, что повышает эффективность индексации.
К примеру, «Clean-param: highlight /forum/showthread.php» преобразует ссылку «/forum/showthread.php?t=30146&highlight=chart» в «/forum/showthread.php?t=30146» и таким образом не будет добавлять дубликат страницы форума с параметром подсветки найденного текста в ветке форума.
User-Agent: * Clean-param: p /forum/showthread.php Clean-param: highlight /forum/showthread.php
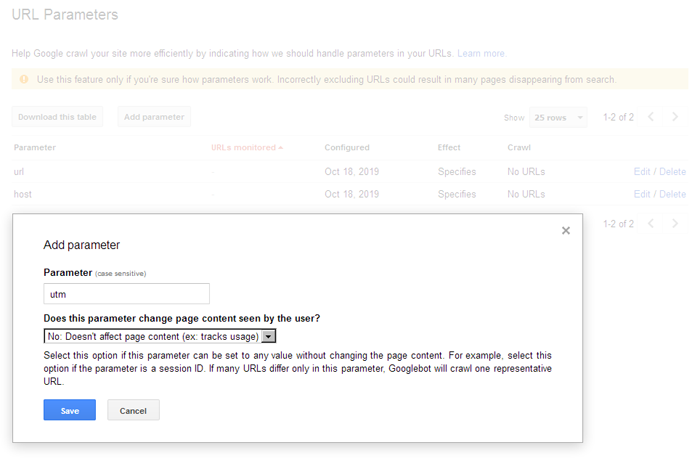
Clean-param используется исключительно для Яндекса, Гугл же использует настройки URL в Google Search Console. У гугла это осуществляется намного проще, простым добавлением параметров в интерфейсе вебмастера:
Crawl-delay
Данная инструкция относится к поисковой системе Яндекс и указывает правила по интенсивности его сканирования поисковым роботом. Это бывает полезно, если у вас слабый хостинг и роботы сильно нагружают сервер. В таком случае, вы можете указать им правило сканировать сайт реже, прописав интервалы между запросами к веб-сайту.
К примеру, Crawl-delay: 10 – это указание сканеру ожидать 10 секунд между каждым запросом. 0.5 – пол секунды.
User-Agent: * Crawl-delay: 10 # Crawl-delay: 0.5
Robots.txt для WordPress
Ниже выложен пример robots.txt для сайта на WordPress. Стандартно у Вордпресс есть три основных каталога:
- /wp-admin/
- /wp-includes/
- /wp-content/
Папка /wp-content/ содержит подпапку «uploads», где обычно размещены медиа-файлы, и этот основной каталог целиком блокировать не стоит:
User-agent: * Disallow: /wp-admin/ Disallow: /wp-includes/ Disallow: /wp-content/ Allow: /wp-content/uploads/
Данный пример блокирует выбранные служебные папки, но при этом позволяет сканировать подпапку «uploads» в «wp-content».
Настройка robots.txt для Google и Яндекс
Желательно настраивать директивы для каждой поисковой системы отдельно, как минимум, их стоит настроить для Яндекса и Гугл, а для остальных указать стандартные значения со звездочкой *.
User-agent: * User-agent: Yandex User-agent: Googlebot
Настройка robots.txt для Яндекса
В некоторых роботс иногда можно встретить устаревшую директиву Host, предназначенную для указания основной версии (зеркала) сайта. Данная директива устарела, поэтому ее можно не использовать (теперь поисковик определяет главное зеркало по 301-м редиректам):
User-agent: Yandex Disallow: /search Disallow: /profile Disallow: */feed Host: https://project.com # необязательно
Воспользуйтесь бесплатным инструментом Яндекса для автоматической проверки корректности настроек роботса.
Настройка robots.txt для Google
Принцип здесь тот же, что и у Яндекса, хоть и со своими нюансами. К примеру:
User-agent: Googlebot Disallow: /search Disallow: /profile Disallow: */feed Allow: *.css Allow: *.js
Важно: для Google мы добавляем возможность индексации CSS-таблиц и JS, которые важны именно для этой поисковой системы (поисковик умеет рендерить яваскрипт, соответственно может получить из него дополнительную информацию, имеющую пользу для сайта, либо просто для понимания, для чего служит тот или ной скрипт на сайте).
По ссылке в Google Webmaster Tools вы можете убедиться, правильно ли настроен ваш robots.txt для Гугла.
Запрет индексирования через Noindex и X-RobotsTag
В некоторых случаях, поисковая система Google может по своему усмотрению добавлять в индекс страницы, запрещенные к индексации через robots.txt (например, если на страницу стоит много внешних ссылок и размещена полезная информация).
Цитата из справки Google:

Для 100% скрытия нежелаемых страниц от индексации, используйте мета-тег NOINDEX.
Noindex – это мета-тег, который сообщает поисковой системе о запрете индексации страницы. В отличие от роботса, он является более надежным, поэтому для скрытия конфиденциальной информации лучше использовать именно его:
- <meta name="robots" content="noindex">
Чтобы скрыть страницу только от Google, укажите:
- <meta name="googlebot" content="noindex">
X-Robots-Tag
Тег x-robots позволяет вам управлять индексированием страницы в заголовке HTTP-ответа страницы. Данный тег похож на тег meta robots и также не позволяет роботам сканировать определенные виды контента, например, изображения, но уже на этапе обращения к файлу, не скачивая его, и, таким образом, не затрачивая ценный краулинговый ресурс.
Для настройки X-Robots-Tag необходимо иметь минимальные навыки программирования и доступ к файлам .php или .htaccess вашего сайта. Директивы тега meta robots также применимы к тегу x-robots.
<?
header("X-Robots-Tag: noindex, nofollow");
?>
Примечание: X-Robots-Tag эффективнее, если вы хотите запретить сканирование изображений и медиа-файлов. Применимо к контенту лучше выбирать запрет через мета-теги. Noindex и X-Robots Tag это директивы, которым поисковые роботы четко следуют, это не рекомендации как robots.txt, которые по определению можно не соблюдать.
Как быстро составить роботс для нового сайта с нуля?
Очень просто – скачать у конкурента! )

Просто зайдите на любой интересующий сайт и допишите в адресную строку /robots.txt, — так вы увидите, как это реализовано у конкурентов. При этом не стоит бездумно копировать их содержимое на свой сайт, ведь корректно настроенные директивы чужого сайта могут негативно подействовать на индексацию вашего веб-ресурса, поэтому желательно хотя бы немного разбираться в принципах работы роботс.тхт, чтобы не закрыть доступ к важным разделам.
И главное: после внесения изменений проверяйте robots.txt на валидность (соответствие правилам). Тогда вам точно не нужно будет опасаться за корректность индексации вашего сайта.
Другие примеры настройки Robots.txt
User-agent: Googlebot Disallow: /*?* # закрываем от индексации все страницы с параметрами Disallow: /users/*/photo/ # закрываем от индексации адреса типа "/users/big/photo/", "/users/small/photo/" Disallow: /promo* # закрываем от индексации адреса типа "/promo-1", "/promo-site/" Disallow: /templates/ #закрываем шаблоны сайта Disallow: /*?print= # версии для печати Disallow: /*&print=
Запрещаем сканировать сервисам аналитики Majestic, Ahrefs, Yahoo!
User-agent: MJ12bot Disallow: / User-agent: AhrefsBot Disallow: / User-agent: Slurp Disallow: /
Настройки robots для Opencart:
User-agent: * Disallow: /*route=account/ Disallow: /*route=affiliate/ Disallow: /*route=checkout/ Disallow: /*route=product/search Disallow: /index.php?route=product/product*&manufacturer_id= Disallow: /admin Disallow: /catalog Disallow: /download Disallow: /registration Disallow: /system Disallow: /*?sort= Disallow: /*&sort= Disallow: /*?order= Disallow: /*&order= Disallow: /*?limit= Disallow: /*&limit= Disallow: /*?filter_name= Disallow: /*&filter_name= Disallow: /*?filter_sub_category= Disallow: /*&filter_sub_category= Disallow: /*?filter_description= Disallow: /*&filter_description= Disallow: /*?tracking= Disallow: /*&tracking= Allow: /catalog/view/theme/default/stylesheet/stylesheet.css Allow: /catalog/view/theme/default/css/main.css Allow: /catalog/view/javascript/font-awesome/css/font-awesome.min.css Allow: /catalog/view/javascript/jquery/owl-carousel/owl.carousel.css Allow: /catalog/view/javascript/jquery/owl-carousel/owl.carousel.min.js

Автор статьи Андрей Симагин
Опыт в SEO и маркетинге более 15 лет. Основные направления деятельности: разработка ПО, инструментов и веб-сервисов для SEO (SiteAnalyzer, SEO Tools, ВордЧекер, Вордстат Extension). Услуги продвижения сайтов в... →
Другие статьи:




















{kind=link}