



 3,231
3,231В статье рассмотрены три распространенных типа ошибки «Не проиндексировано» в Google, о которых должен знать каждый SEO-специалист, а также способы их устранения.

Вероятно, вы когда-нибудь задумывались, почему некоторые из важных страниц сайта не индексируются в Google?
Несмотря на наличие всех нужных URL в карте сайта Sitemap.xml и соблюдения основных правил SEO, многие страницы по-прежнему попадают во всеми нелюбимую категорию «Не проиндексировано» в Google Search Console.
В этой статье зарубежный SEO-специалист Адам Гент (Adam Gent) расскажет о 3-х распространенных причинах неиндексации страниц, о которых должен знать каждый сеошник, а также о том, как определить, к какой категории относятся ваши страницы.
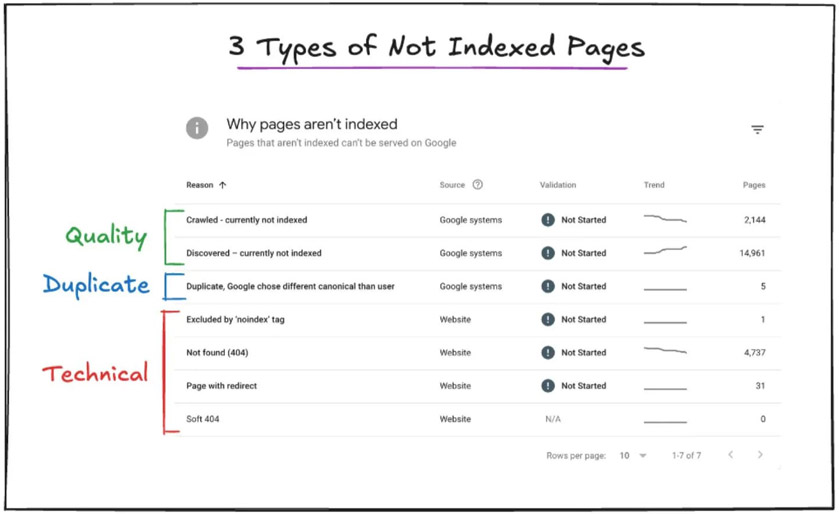
✋ Три типа неиндексации страниц
Можно разделить неиндексированные страницы на 3 типа:
1. Технические
Ошибки «Не индексировано» связаны со страницами, которые либо не соответствуют основным техническим требованиям Google, либо имеют директивы, запрещающие Google индексировать страницу.
2. Дублирование
Ошибки «Не индексировано» относятся к страницам, которые запускают алгоритм канонизации Google, и канонический URL выбирается из группы дубликатов страниц.
3. Качество
Ошибки «Не индексировано» связаны со страницами, которые активно удаляются из результатов поиска Google и со временем «забываются».
Рассмотрим каждый из вариантов.
🆚 Важные и неважные страницы
Прежде чем погрузиться в изучение причин неиндексации, давайте выделим важные и неважные страницы. При устранении проблем с индексацией всегда следует разделять страницы на два типа:
- Важные страницы.
- Неважные страницы.
🥇 Важная страница
Важная страница – это тип страниц, которые должны:
- Появляться в результатах поиска, чтобы способствовать привлечению трафика и повышению продаж.
- Помогать передаче ссылочных сигналов на другие важные страницы (например, /blog/).
Например, если вы являетесь владельцем интернет-магазина, то вы хотите, чтобы страницы ваших товаров сканировались, индексировались и ранжировались по релевантным ключевым словам.
При этом, вы также хотите, чтобы ваша страница /blog/ была проиндексирована для того, чтобы она передавала PageRank (ссылочные сигналы) вашим постам в блоге. Таким образом, эти важные типы страниц также могут появляться в результатах поиска и привлекать SEO-трафик.
😒 Неважная страница
Неважные страницы – это страницы, которые не должны:
- Появляться в результатах поиска.
- Тратить бюджет сканирования Googlebot.
- Передавать ссылочные сигналы на другие страницы.
Это не значит, что мы полностью игнорируем эти страницы. Просто это означает, что мы не тратим время на то, чтобы индексировать данные типы страниц в Google.
Например, многие системы управления контентом сайта (CMS) по умолчанию генерируют строки запросов (URL с параметрами), которые Google может сканировать и индексировать. И нам нужно правильно обрабатывать эти URL-адреса, чтобы Google не индексировал подобные страницы.
🧡 Как определить важные и неважные страницы?
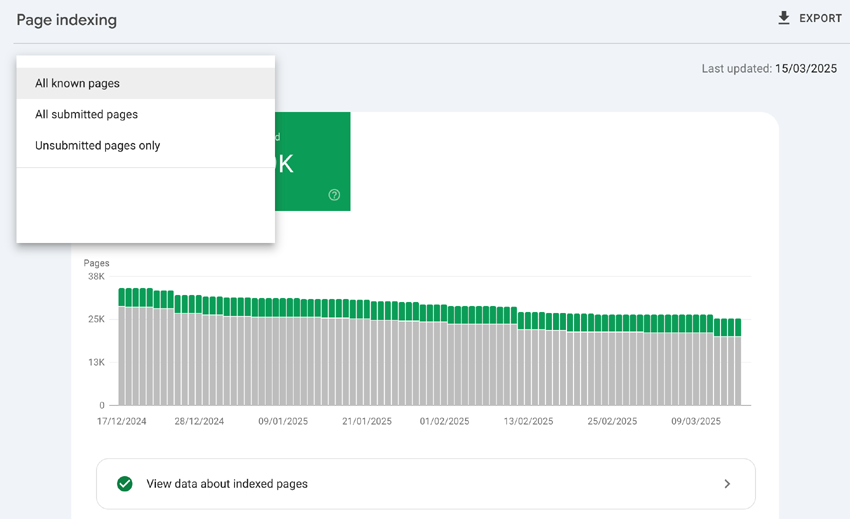
Лучший способ отделить важные и неважные страницы – использовать карты сайта Sitemap.xml.
Карта сайта Sitemap.xml, содержащая важные страницы, отправленные в Google Search Console, позволит отфильтровать данные в отчете об индексации страниц по отправленным (важным) и неотправленным (неважным) страницам.
Что ж, теперь давайте приступим!
1️⃣ Минимальные технические требования
Первый тип ошибок касается минимальных технических требований для индексации.
Что это за типы ошибок?
Подобные страницы либо не соответствуют основным техническим требованиям Google, либо содержат директивы, которые явно предписывают Google не индексировать их:
- Ошибка сервера (5xx)
- Ошибка настройки редиректа
- URL заблокирован в Robots.txt
- URL помечен как «Noindex»
- Мягкий 404 (Soft 404)
- Заблокировано из-за несанкционированного запроса (401)
- Не найдено (404)
- Заблокировано из-за запрета доступа (403)
- URL заблокирован из-за другой проблемы 4xx
- Страница с редиректом (3xx)
Почему страницы сгруппированы в эту категорию?
Google обнаружил, что страница не соответствует минимальным техническим требованиям.
Чтобы страница была проиндексирована, она должна соответствовать следующим техническим требованиям:
- Googlebot не должен быть заблокирован.
Страница работает, то есть Google получает код статуса HTTP 200 (OK).
- Страница имеет индексируемый контент.
Если сгруппировать технические ошибки в Google Search Console, то они соответствуют одному из минимальных требований:
Googlebot не заблокирован:
- URL заблокирован в файле Robots.txt
- Заблокировано из-за несанкционированного запроса (401)
- Заблокировано из-за запрета доступа (403)
- URL заблокирован из-за другой проблемы 4xx
Google получает код статуса HTTP 200 (OK):
- Ошибка сервера (5xx)
- Ошибка настройки редиректа
- Не найдено (404)
- Страница с редиректом (3xx)
Страница имеет индексируемый контент:
- URL помечен как «Noindex»
- Мягкий 404 (Soft 404)
Как можно исправить эти ошибки?
Как правило, исправление таких непроиндексированных страниц находится под вашим контролем.
Теперь, когда мы сгруппировали эти ошибки по определенным категориям, их будет легче выявлять и устранять.
1. Googlebot не заблокирован
Если важная страница возвращает данный тип ошибки, убедитесь, что она может быть просканирована Googlebot. Важная страница может быть заблокирована, когда:
- Правило Robots.txt блокирует сканирование страницы
- CDN мягко или жестко блокирует Googlebot
- Страница была скрыта за авторизацией
Вы можете проверить, заблокирована ли важная страница, с помощью инструмента анализа Robots.txt и узнать больше о том, как отладить CDN и сканирование.
2. Google получает код статуса HTTP 200 (OK)
Если важная страница не возвращает код статуса HTTP 200 (OK), то Googlebot не будет индексировать страницу.
Существует 3 причины, по которым важная страница возвращает код статуса, отличный от 200:
- Статус, отличный от 200, не является преднамеренным (и должен возвращать код статуса 200).
- Статус, отличный от 200, установлен намеренно (и Sitemap.xml не был обновлен).
- Страница возвращает код статуса 200, но Googlebot не выполнил повторное сканирование страницы.
Если важная страница непреднамеренно возвращает код статуса, отличный от 200, это может быть связано с тем, что страница была перенаправлена по коду 3xx, который, в свою очередь, вернул ошибку 4xx или 5xx. Вы можете прочитать больше о том, как различные коды статуса HTTP влияют на Googlebot.
Сайт на JavaScript также может возвращать неправильные коды статуса для важных страниц. Вы можете прочитать больше о передовых методах JavaScript SEO и кодах статуса HTTP в официальной документации Google.
И не паникуйте, если Google возвращает ошибку с кодом статуса HTTP, отличным от 200 для одной из важных страниц сайта. Особенно, если вы знаете, что страница (или страницы) были недавно изменены.
Иногда Googlebot не сканирует страницу или отчетам требуется время, чтобы отразить изменения, внесенные на сайт.
Проверьте с помощью Live URL test в инструменте проверки URL в Google Search Console.
3. Страница имеет индексируемый контент
Наконец, если важные страницы сайта не имеют индексируемого контента, то обычно это происходит по следующим причинам:
- Googlebot обнаружил на странице тег Noindex.
- Googlebot проанализировал контент и считает, что это мягкая ошибка 404 (Soft 404).
Если важная страница имеет тег Noindex (meta robots или X-Tobots-Tag), то Google не будет отображать или индексировать страницу. Узнать больше о теге Noindex можно в официальной документации Google.
Если на важной странице возникает ошибка Soft 404, это означает, что Google считает, что контент должен возвращать ошибку 404. Обычно это происходит потому, что Google обнаруживает схожий минимальный контент на нескольких страницах, из-за чего он считает, что страницы должны возвращать ошибку 404.
Дополнительную информацию об исправлении программных ошибок 404 можно найти в официальной документации Google.
2️⃣ Дублированный контент
Второй тип неиндексированных страниц связан с проблемами дублирования контента.
Что это за типы ошибок?
Данные типы ошибок связаны с процессом канонизации Google во время индексации страниц:
- Альтернативная страница с правильным каноническим тегом. На странице указано, что каноническим URL, который будет отображаться в результатах поиска, является другая страница.
- Дубликат без выбранного пользователем канонического URL. Google обнаружил, что данная страница является дубликатом другой страницы, у нее нет выбранного пользователем канонического URL и в качестве канонического URL выбрана другая страница.
- Дубликат, так как Google выбрал канонический адрес, отличный от указанного пользователем. Хотя вы указали другую страницу в качестве канонического URL, Google выбрал другую страницу в качестве канонического URL для отображения в результатах поиска.
Почему страницы сгруппированы в эту категорию?
Страницы сгруппированы в эту категорию из-за алгоритма канонизации Google.
Когда Google обнаруживает дубликаты страниц на вашем сайте, то он:
- Группирует страницы в кластер.
- Анализирует канонические сигналы вокруг страниц в кластере.
- Выбирает канонический URL из кластера для отображения в результатах поиска.
Этот процесс называется канонизацией. Однако этот процесс не статичен.
Google непрерывно оценивает канонические сигналы, чтобы определить, какой URL должен быть каноническим URL для кластера. Он смотрит на:
- 3xx редиректы
- Включение Sitemap.xml
- Канонические сигналы мета-тегов
- Внутренние шаблоны ссылок
- Настройки структуры URL
Если страница ранее была каноническим URL-адресом, а новые сигналы заставляют Google выбирать другой URL в кластере, то ваша исходная страница удаляется из результатов поиска.

Как можно исправить эти ошибки?
Исправление этих типов неиндексированных страниц находится под вашим контролем.
Есть 3 причины, по которым ваши важные страницы появляются в этих категориях:
- Важные страницы не имеют канонического тега.
- Важные страницы были продублированы из-за некорректной структуры сайта (стали дублями).
- Канонические сигналы важных страниц несогласованы на всем сайте.
Дубликат из-за отсутствия тега Canonical
Если важная страница (или страницы) не имеет канонического тега, это может привести к тому, что Google выберет канонический URL-адрес на основе более слабых канонических сигналов.
Всегда проверяйте, что вы указали канонический URL, используя канонические теги. Для получения дополнительной информации вы можете прочитать, как указать каноническую ссылку в документации Google.
Google выбрал другой канонический URL
Если сигналы вокруг важной страницы не согласованы, это может привести к тому, что Google выберет другой URL в качестве канонического URL в кластере.
Даже если вы используете канонический тег.
Вам необходимо убедиться, что канонические сигналы согласованы на вашем сайте для URL, которые вы хотите видеть в результатах поиска. В противном случае Google может выбирать канонический URL за вас. И он может быть не тем, который вы ожидаете видеть в поиске.
Google предоставляет информацию о том, как исправить канонические проблемы, в своей официальной документации.
3️⃣ Проблемы с качеством
Последний тип неиндексированных страниц связан с проблемами качества, и их сложнее всего решить.
Что это за типы ошибок?
Эти типы ошибок индексации делятся на 3 группы в зависимости от сигналов, собираемых вокруг страниц с течением времени:
- Просканировано – в настоящее время не проиндексировано: страница была обнаружена, просканирована, но не проиндексирована или исторически проиндексированная страница была удалена из результатов поиска Google.
- Обнаружена – в настоящее время не проиндексирована: новая страница обнаружена, но еще не просканирована, или Google активно забывает исторически проиндексированную страницу.
- URL неизвестен Google: страница никогда не была просмотрена Google или Google активно «забыл» исторически просканированные и проиндексированные страницы.
Почему страницы сгруппированы в эту категорию?
Google активно удаляет эти страницы из результатов поиска и индекса.
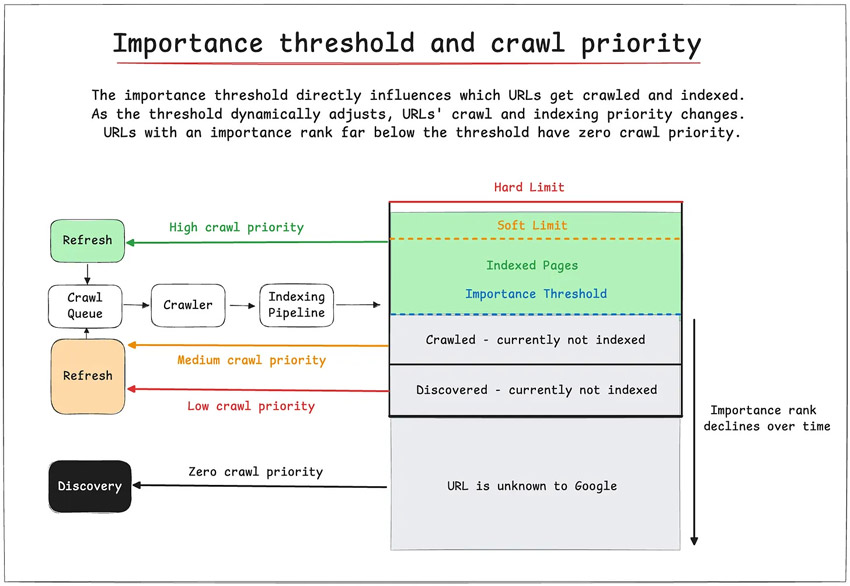
Мягкие ограничения устанавливают целевой показатель количества индексируемых страниц. А порог важности напрямую влияет на то, какие URL-адреса будут просканированы и проиндексированы.
Как это работает согласно патенту при достижении мягкого предела:
- Индексируются страницы с рейтингом важности, равным или превышающим пороговое значение.
- Поскольку пороговое значение динамически корректируется, приоритет сканирования и индексации URL-адресов изменяется.
- URL с рейтингом важности намного ниже порогового значения имеют нулевой приоритет сканирования.
Данная система объясняет, почему некоторые страницы переходят из состояния индексации «Просканировано – в настоящее время не проиндексировано» в состояние «URL неизвестен Google» в Google Search Console.
Все дело в их рейтинге важности относительно текущего порога.
Проблема с категорией качества заключается в том, что она может вводить в заблуждение.
Вам необходимо сгруппировать два типа важных страниц в этой категории, чтобы избежать действий с неважными страницами:
✅ Индексируемые: важные страницы, которые индексируются, но не проиндексированы.
❌ Неиндексируемые: важные страницы, которые не индексируются (301, 404, Noindex и т.п.).
Почему нам необходимо различать эти 2 типа страниц в Google Search Console?
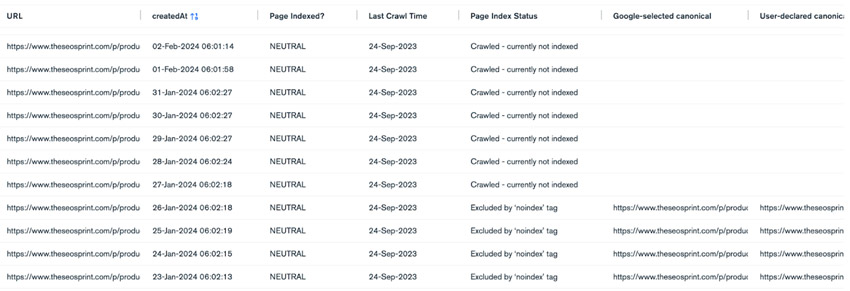
Наши собственные тесты показали, что страницы, которые не индексируются с течением времени, могут быть сгруппированы в эти категории, что делает эти данные нечеткими и менее ценными.
Например, «Исключено тегом Nonindex» может стать «Просканировано – в настоящее время не индексируется» примерно через 6 месяцев. Это не ошибка, а так на самом деле задумано.
Пытаясь выяснить, почему страницы сгруппированы в эту категорию, важно различать, какие страницы индексируются, а какие нет.
Поэтому всегда запускайте сканирование, чтобы проверить данные индексируемости страниц, сгруппированных в эту категорию.
Как исправить ошибки индексируемых страниц?
Важные индексируемые страницы, которые не проиндексированы, будет сложнее исправить.
Почему?
Если страница активна, индексируется и должна ранжироваться в поиске Google, но находится под этой категорией, это означает, что у сайта есть более серьезные проблемы с качеством контента.
По данным Google – он активно «забывает» некачественные страницы из-за сигналов, полученных с течением времени.
Существует 2 типа сигналов, которые могут повлиять на то, почему Google может забыть ваши важные индексируемые страницы:
- Сигналы на уровне страницы
- Сигналы на уровне домена
📄 Сигналы на уровне страницы
Сигналы на уровне страницы можно сгруппировать по трем проблемам:
- Индексируемые страницы не имеют уникального индексируемого контента.
- Индексируемые страницы не имеют ссылок с других важных страниц.
- Индексируемые страницы не ранжировались по запросам и не привлекали релевантных кликов.
Почему важны именно эти три сигнала на уровне страницы?
Сам Google описывает три основных принципа ранжирования так:
📄 Контент: текст, метаданные и активы, используемые на странице.
🔗 Ссылки: качество ссылок и слов, используемых в анкорном тексте, указывающем на страницу.
🖱 Клики: взаимодействия пользователя (клики, свайпы, запросы) со страницей в результатах поиска.
В ходе судебного разбирательства в Министерстве юстиции Google предоставила наглядный слайд, на котором было подчеркнуто, что контент (внедрение векторов), взаимодействие с пользователем (модели кликов) и анкоры (PageRank / анкорный текст) играют ключевую роль во всех их системах.
Важным сигналом, используемым при ранжировании и индексировании, являются данные о взаимодействии с пользователем.
Документы DOJ описывают, как Google использует «данные на стороне пользователя» для определения того, какие страницы следует поддерживать в индексе. Кроме того, в другом документе DOJ упоминается, что данные на стороне пользователя, в частности данные запроса, определяют место документа в индексе.
Данные запроса для определенных страниц могут указывать на то, сохраняется ли страница как «индексированная» или «неиндексированная».
Что это значит?
Это означает, что для важных страниц вы должны включать уникальный индексируемый контент, который соответствует намерению пользователя, и создавать ссылки на страницу с проверенным анкорным текстом. Эти действия необходимы для ранжирования по запросам, которые ищут ваши клиенты.
Взаимодействие пользователя с вашей страницей, скорее всего, определит, останется ли она индексируемой с течением времени.
При просмотре важных индексируемых страниц, которые Google активно удаляет, обратите внимание на:
- Возможность индексации URL. Проверьте, может ли робот Googlebot сканировать URL страницы и отображать контент, используя тест Live URL в инструменте проверки URL-адресов в Google Search Console.
- Качество контента. Проверьте, соответствуют ли страница или страницы, которые вы хотите ранжировать, качеству и намерениям пользователя целевых ключевых слов (отличная статья Keyword Insights на эту тему).
- Внутренние ссылки на страницу. Проверьте, ссылаются ли страницы на другие важные страницы сайта, и используете ли вы разнообразный анкорный текст (отличная статья Кевина Индига на эту тему).
- Пользовательский опыт. Проверьте, действительно ли ваши важные страницы обеспечивают хороший пользовательский опыт, быстро загружаются и отвечают ли на вопросы пользователей (отличная статья от Seer Interactive на эту тему).
🌐 Сигналы на уровне домена
Однако сигналы на уровне страницы – не единственный фактор, имеющий значение.
Новое исследование специалистов по поисковой оптимизации показало, что сигналы на уровне домена, такие как «бренд», влияют на ранжирование сайта, что, как упоминалось выше, в конечном итоге влияет на индексацию.
Сигналы на уровне домена можно разбить на три блока:
- Страницы являются частью проблемы качества всего сайта.
- Страницы находятся на сайте, который не привлекает никаких кликов по бренду.
- Страницы / сайт не связаны с другими соответствующими сайтами с высоким рейтингом.
Марк Уильямс Кук и его команда обнаружили эксплойт конечной точки API, который позволил им манипулировать сетевыми запросами Google. Этот эксплойт позволил его команде извлечь метрики для классификации сайтов и запросов в поиске Google.
Одним из наиболее интересных извлеченных показателей стал показатель качества сайта (Site Quality score).
Показатель качества сайта – это показатель, который Google присваивает каждому домену в рейтинге поиска Google и оценивает по шкале от 0 до 1.
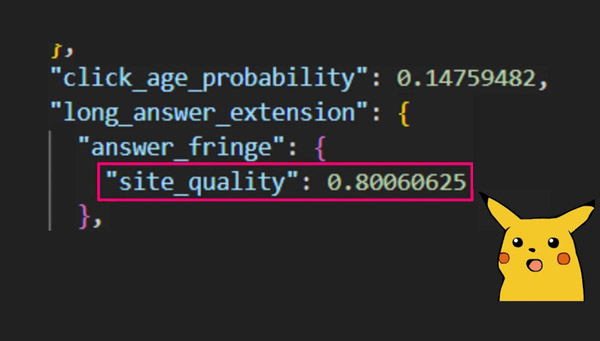
Одним из самых интересных моментов выступления Марка стало то, что при анализе конкретного расширенного результата его команда заметила, что Google показывает только домены, превышающие пороговое значение оценки качества сайта.
Например, его команда заметила, что сайты с показателем качества сайта ниже 0,4 не имели права появляться в расширенных результатах. Независимо от того, насколько вы «оптимизируете» контент, вы не сможете появиться в расширенных результатах без качества сайта выше 0,4.
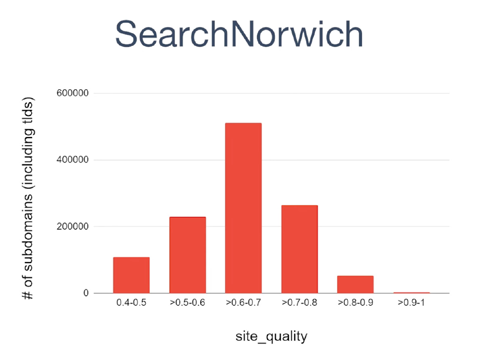
Из чего складывается оценка качества сайта?
Марк указал на патент Google под названием «Показатель качества сайта» (US9031929B1), в котором описаны три показателя, которые можно использовать для расчета показателя качества сайта.
3 показателя, влияющие на оценку качества сайта:
- Объем бренда – как часто люди ищут ваш сайт среди других терминов.
- Клики по бренду – как часто люди переходят на ваш сайт, когда он не является первым результатом поиска.
- Анкорный текст по бренду – как часто название вашего бренда или сайта встречается в анкорном тексте в интернете.
А что, если у вас совершенно новый сайт?
Марк указал на патент Google под названием «Прогнозирование качества сайта» (US9767157B2**), в котором описаны два метода прогнозирования показателей качества сайта для новых сайтов.
Два метода прогнозирования показателя качества сайта для новых сайтов:
- Модели фраз: прогнозирует качество сайта, анализируя фразы, присутствующие на сайте, сравнивая их с моделью, созданной на основе ранее оцененных сайтов.
- Данные о запросах пользователей: используя исторические модели кликов, прогнозирование показателя качества сайта на основе того, как пользователи взаимодействуют с конкретным сайтом.
Существуют ли какие-либо данные или исследования, подтверждающие показатель качества сайта?
Интересно, что Том Каппер из Moz изучил основные обновления Google и обнаружил, что обновление справочного контента (HCU) повлияло на сайты с низким соотношением авторитета бренда и авторитета домена.
Это означает, что обновления ядра сильнее повлияли на сайты с низким авторитетом бренда.
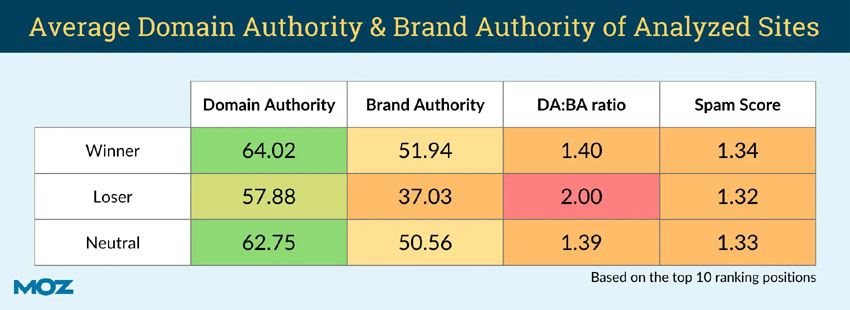
Google не использует метрику авторитета бренда от Moz в своих алгоритмах ранжирования. Однако исследование Тома показывает связь между «авторитетом» бренда вашего домена и способностью сайта ранжироваться в поиске Google.
Почему качество сайта или авторитет бренда имеют значение для индексации?
Соберем все тезисы в одном месте, чтобы мы могли над этим поразмыслить:
- Google использует индексируемый контент, анкорный текст и ссылки для ранжирования страниц по запросам.
- Со временем Google использует «данные на стороне пользователя» (модели кликов / данные запросов), чтобы определить, остается ли страница в индексе на уровне страницы.
- Google отслеживает показатель качества вашего домена (сайта), и только сайты, превышающие определенный порог (=> 0,4), могут отображаться в таких блоках, как расширенные результаты поиска.
- На основе патента Google показатель качества сайта рассчитывается на основе объема бренда, кликов и взаимодействий (а также прогнозируемых показателей для новых сайтов).
- Согласно исследованию Moz, обновление контента справки Google (HCU) влияет на сайты с низким авторитетом бренда, но высоким авторитетом обратных ссылок.
- Если на сайт или страницы влияют обновления Google (например, HCU), они не будут ранжироваться по запросам пользователей и со временем будут иметь меньше «данных на стороне пользователя».
- Чем меньше «данных на стороне пользователя» с течением времени, тем больше вероятность того, что поисковый индекс Google примет решение об активном удалении страницы из результатов поиска.
Сигналы на уровне домена, такие как бренд и обратные ссылки, помогают важным индексируемым страницам ранжироваться в поиске.
Благодаря ранжированию в результатах поиска важные страницы получат «данные пользователя» (клики и запросы), что увеличит вероятность того, что ваши страницы останутся в индексе Google.
Сигналы на уровне домена влияют на рейтинг, влияя на то, останутся ли важные страницы в индексе.
Если изменения на уровне страниц не улучшают статус индексации важных страниц, возможно, вам следует поработать над повышением авторитета сайта и бренда.
Вот почему так много корпоративных сайтов страдают от раздувания индекса.
Google с радостью сканирует и индексирует страницы низкого качества на сайтах с более высокими показателями качества (но это тема для другой статьи).
Это неприятно признавать, но реальность такова, что Google предпочитает ранжировать бренды, а не небольшие сайты.
📌 Резюме
Существует 3 основных типа неиндексации страниц: технические ошибки, проблемы с дублированием контента и проблемы с качеством.
Технические ошибки и проблемы с дублированием контента, как правило, поддаются контролю и могут быть устранены с помощью стандартных методов оптимизации.
Однако вопросы качества требуют более глубокого анализа и часто указывают на более серьезные проблемы с тем, насколько ваш контент соответствует ожиданиям пользователей и поисковых систем.
Регулярный мониторинг статуса индексации имеет решающее значение для определения категории, к которой относятся ваши неиндексированные страницы, и принятия соответствующих мер.
Оригинал материала взят с сайта Adam Gent
Другие статьи:




















{kind=link}