



 7,613
7,613Вопрос определения дубликатов страниц и уникальности текстов внутри сайта является одним из важнейших в списке работ по техническому аудиту. От наличия дублей страниц зависит как общее самочувствие сайта, так и распределение краулингового бюджета поисковых систем, возможно расходуемого впустую, да и в целом ранжирование сайта может испытывать трудности из-за большого числа дублированного контента.

И если для проверки уникальности отдельных текстов в интернете можно легко найти большое количество сервисов и программ, то для проверки уникальности группы определенных URL между собой подобных сервисов существует не много, хотя сама по себе проблема является важной и актуальной.
Какие варианты проблем с не уникальным контентом могут быть на сайте?
1. Одинаковый контент по разным URL.
Обычно это страница с параметрами и та же самая страница, но в виде ЧПУ (человеко-понятный УРЛ).
- Пример:
- https://site.ru/index.php?page=contacts
- https://site.ru/contacts/
Это достаточно распространенная проблема, когда после настройки ЧПУ, программист забывает настроить 301 редирект со страниц с параметрами на страницы с ЧПУ.
Данная проблема легко решается любым веб-краулером, которой сравнив все страницы сайта, обнаружит, что у двух из них одинаковые хеш-коды (MD5), и сообщит об этом оптимизатору, которому останется поставить задачу, все тому же программисту, на установку 301 редиректов на страницы с ЧПУ.
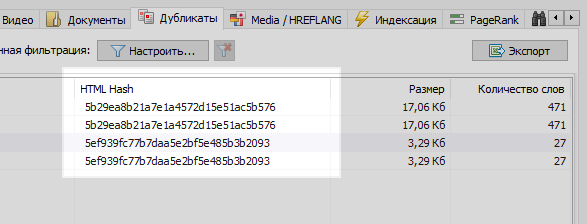
Однако не все бывает так однозначно.
2. Частично совпадающий контент.
Подобный контент образуется, когда мы имеем разные страницы, но, по сути, с одинаковым или схожим содержанием.
Пример 1
На сайте по продаже пластиковых окон, в новостном разделе, копирайтер год назад написал поздравление с 8 марта на 500 знаков и дал скидку на установку пластиковых окон в 15%.
А в этом году контент-менеджер решил "схалтурить", и не мудрствуя лукаво, нашел ранее размещенную новость со скидками, скопировал ее, и заменил размер скидки с 15 на 12% + дописал от себя 50 знаков с дополнительными поздравлениями.
Таким образом, в итоге мы имеем два практически идентичных текста, схожих на 90%, которые сами по себе являются нечеткими дубликатами, одному из которых по хорошему требуется срочный рерайт.

При этом, для сервисов технического аудита данные две новости будут разными, так как ЧПУ на сайте уже настроены, и контрольные суммы у страниц не совпадут, как ни крути.
В итоге, какая из страниц будет ранжироваться лучше – большой вопрос...
Но новости они такие – имеют свойство быстро устаревать, поэтому возьмем пример поинтереснее.
Пример 2
У вас на сайте есть статейный раздел, либо вы ведете личную страничку по своему хобби / увлечению, например это "кулинарный блог".
И, к примеру, в вашем блоге набралось уже порядком статей за все время, более 100, а то и вовсе несколько сотен. И вот вы подобрали тему и написали новую статью, разместили, а впоследствии каким-то образом обнаружилось, что аналогичная статья уже была написана 3 года назад. Хотя, казалось бы, перед написанием контента вы пробежались по всем названиям, открыли Excel со списком размещенных тем, но не учли, что прошлое содержимое статьи "Как приготовить горячий шоколад в домашних условиях" сильно совпадает с только что написанным материалом. А при проверке этих двух статей в одном из онлайн-сервисов получается, что они уникальны между собой на 78%, что, конечно же, не хорошо, так как из-за частичного дублирования возникает канибализация поисковых запросов между этими страницами, а у поисковой системы возникают вопросы и сложности при ранжировании подобных дублей.

Само собой, каждый копирайтер после написания статьи должен проверять ее на уникальность в одном из известных сервисов, а каждый СЕОшник обязан проверять новый контент при размещении на сайте в тех же сервисах.
Но, что делать, если к вам только-только пришел сайт на продвижение и вам нужно оперативно проверить все его страницы на дубли? Либо, на заре открытия своего блога вы написали кучу однотипных статей, а теперь, скорее всего из-за них сайт начал проседать. Не проверять же руками 100500 страниц в онлайн сервисах, добавляя на проверку каждую статью руками и затрачивая на это уйму времени.
BatchUniqueChecker
Именно для этого мы и создали программу BatchUniqueChecker, предназначенную для пакетной проверки группы URL на уникальность между собой.
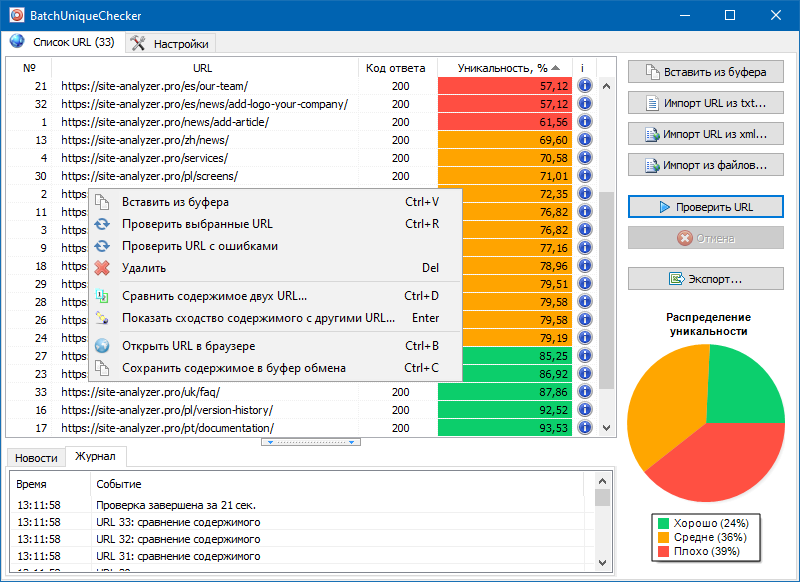
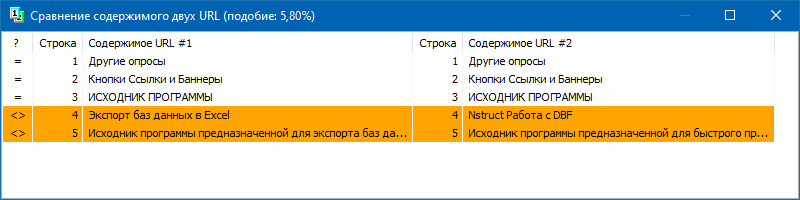
Принцип работы BatchUniqueChecker прост: по заранее подготовленному списку URL программа скачивает их содержимое, получает PlainText (текстовое содержимое страницы без блока HEAD и без HTML-тегов), а затем при помощи алгоритма шинглов сравнивает их друг с другом.
Таким образом, при помощи шинглов мы определяем уникальность страниц и можем вычислить как полные дубли страниц с 0% уникальностью, так и частичные дубли с различными степенями уникальности текстового содержимого.
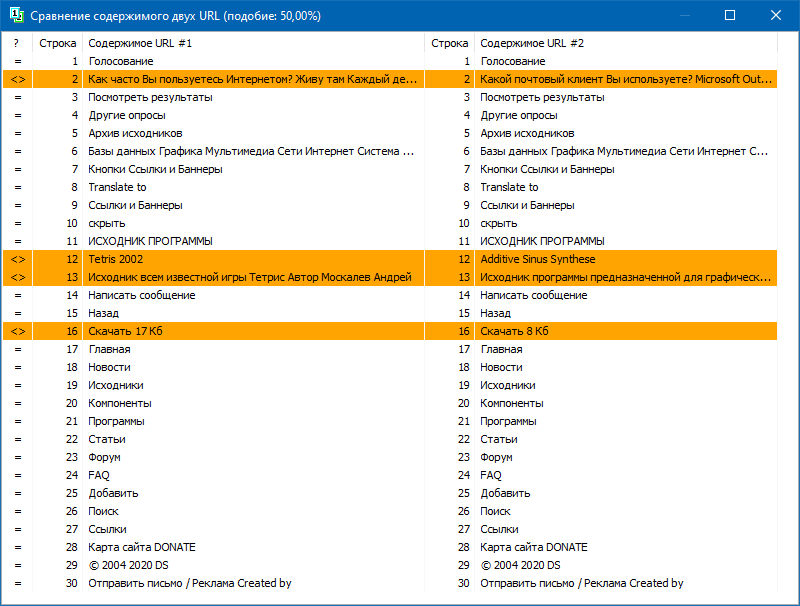
В настройках программы есть возможность ручной установки размера шингла (шингл – это количество слов в тексте, контрольная сумма которых попеременно сравнивается с последующими группами внахлест). Мы рекомендуем установить значение = 4. Для больших объемов текста от 5 и выше. Для относительно небольших объемов – 3-4.
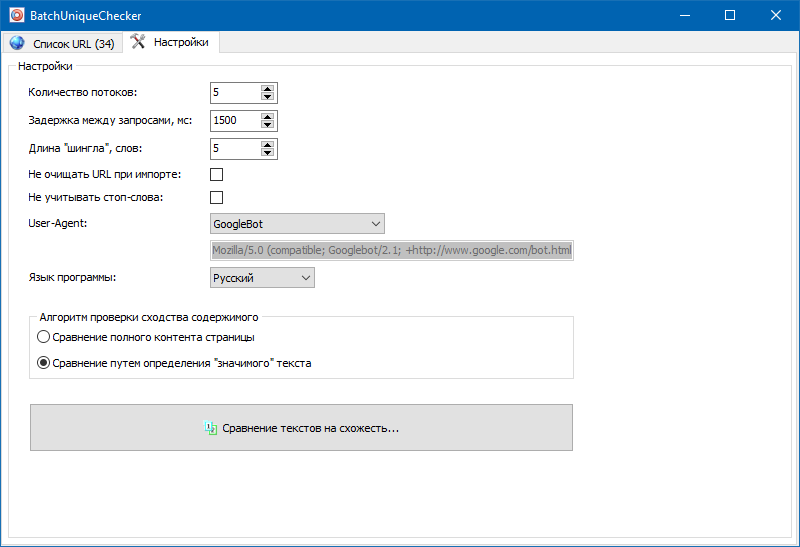
Значимые тексты
Помимо полнотекстового сравнения контента, в программу заложен алгоритм "умного" вычленения так называемых "значимых" текстов.
То есть, из HTML-кода страницы мы получаем только лишь контент, содержащийся в тегах H1-H6, P, PRE и LI. За счет этого мы как бы отбрасываем все "не значимое", например, контент из меню навигации сайтов, текст из футера либо бокового меню.
В результате подобных манипуляций мы получаем только "значимый" контент страниц, который при сравнении покажет более точные результаты уникальности с другими страницами.
Список страниц для их последующего анализа можно добавить несколькими способами: вставить из буфера обмена, загрузить из текстового файла, либо импортировать из Sitemap.xml с диска вашего компьютера.
Благодаря многопоточной работе программы, проверка сотни и более URL может занять всего несколько минут, на что в ручном режиме, через онлайн-сервисы, мог бы уйти день или более.
Таким образом, вы получаете простой инструмент для оперативной проверки уникальности контента для группы URL, который можно запускать даже со сменного носителя.
Программа BatchUniqueChecker бесплатна, занимает всего 4 Мб в архиве и не требует установки.
Все что необходимо для начала работы – скачать дистрибутив и добавить на проверку список интересующих URL, которые можно получить через бесплатную программу технического аудита SiteAnalyzer.
Программа BatchUniqueChecker внедрена в SiteAnalyzer в виде отдельного модуля и в текущем виде более развиваться не будет. Подробнее...

Автор статьи Андрей Симагин
Опыт в SEO и маркетинге более 15 лет. Основные направления деятельности: разработка ПО, инструментов и веб-сервисов для SEO (SiteAnalyzer, SEO Tools, ВордЧекер, Вордстат Extension). Услуги продвижения сайтов в... →
Другие статьи:
![]() Dmitry0904
Dmitry0904
11.04.2025 19:36:25
Статья интересная, но сейчас мало кто будет скачивать себе на комп ПО сомнительного происхождения есть куча сайтов где можно проверить уникальность чего угодно, сама пользуюсь https://анти-антиплагиат.рф/
Чтобы оставить комментарий необходимо авторизоваться.




















{kind=link}